prima.cpp is a distributed implementation of llama.cpp.
First, prepare the cluster. Then download the model, which takes some time (using qwen2.5-7b-instruct-q8_0.gguf as an example). Currently, the following model list is supported, with only three quantization formats: Q4KM, Q6K, Q80. It is not recommended to download Q4KM quantization format models at present, as when loading Q4_K_M (Q4KM) models, the framework detects no corresponding operator for the tensor’s ftype enumeration and triggers an assertion exception “ggml_blck_size(type) == 0”, resulting in a core dump.
Using fping and arp tools to find cluster IP addresses
## Use fping to scan LAN clients
fping -a 192.168.2.1 192.168.2.255 -g -q
## Then use arp to view MAC addresses corresponding to IPs
arp
Based on MAC addresses, we can find the addresses:
- 192.168.2.113
- 192.168.2.116
- 192.168.2.117
- 192.168.2.120
We’ll use 120 as the master node and the rest as worker nodes
Environment Installation
Taking node 120 as an example:
sudo apt update -y && sudo apt install -y gcc-9 make cmake fio git wget libzmq3-dev
Download Model File
wget https://www.modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct-GGUF/resolve/master/qwen2.5-7b-instruct-q8_0.gguf
Install fio
prima.cpp introduces the Halda algorithm, which needs to detect computing power, GPU performance, network bandwidth, and disk before scheduling. The fio tool on the k1 development board lacks libaio, so we need to clone the fio repository and recompile:
sudo apt-get install build-essential pkg-config
git clone https://github.com/axboe/fio.git
cd fio
./configure --prefix=/usr
make -j$(nproc)
sudo make install
Install HIGHS
HIGHS is a high-performance linear optimization library, mainly used in prima.cpp for planning “how many layers for each node, which model layers to put on GPU, which model layers to offload to CPU, etc.” Clone HIGHS:
git clone https://github.com/ERGO-Code/HiGHS.git
cd HiGHS
mkdir build && cd build
cmake ..
make -j$(nproc)
sudo make install
Clone prima.cpp Repository
git clone https://github.com/Lizonghang/prima.cpp.git
cd prima.cpp
make USE_HIGHS=1 -j$(nproc)
The other three worker nodes need to follow these steps to install the environment
Deploy Large Model
Run the following commands on the four hosts respectively, with 120 as the master node and the others as workers, structured as follows:

Commands to start each node:
##192.168.2.120: rank0
./llama-cli -m ~/prima/qwen2.5-7b-instruct-q8_0.gguf -c 1024 --world 4 -p "what is edge AI?" --rank 0 --master 192.168.2.120 --next 192.168.2.113
##192.168.2.113: rank1
./llama-cli -m ~/prima/qwen2.5-7b-instruct-q8_0.gguf -c 1024 --world 4 --rank 1 --prefetch --master 192.168.2.120 --next 192.168.2.116
##192.168.2.116: rank2
./llama-cli -m ~/prima/qwen2.5-7b-instruct-q8_0.gguf -c 1024 --world 4 --rank 2 --prefetch --master 192.168.2.120 --next 192.168.2.117
##192.168.2.117: rank3
./llama-cli -m ~/prima/qwen2.5-7b-instruct-q8_0.gguf -c 1024 --world 4 --rank 3 --prefetch --master 192.168.2.120 --next 192.168.2.120
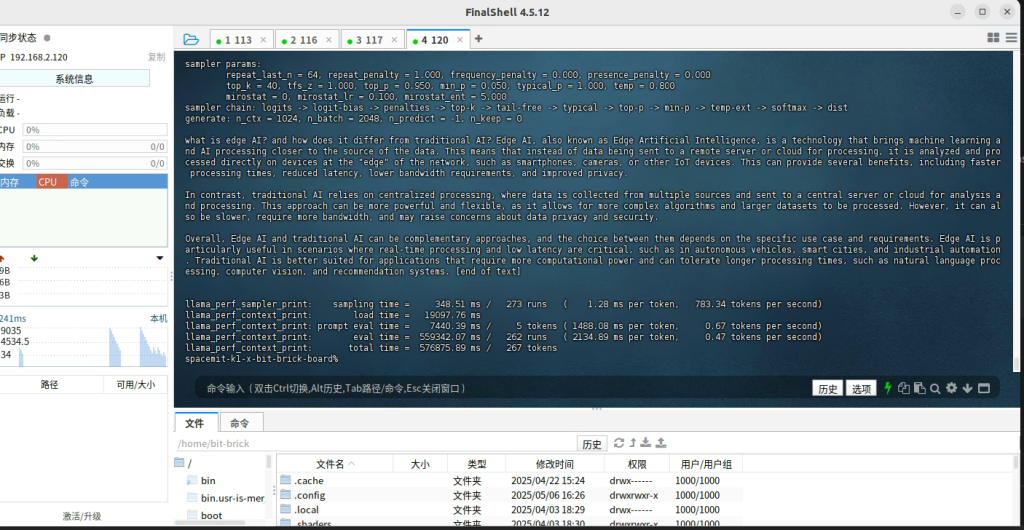
Running effect as shown:
Thanks to 麻瓜 for providing ideas and answering questions


1111