Running handwritten digit recognition on K1 [2] The above article introduced the model training using the mnist dataset. Now let’s convert the trained model into tflite so that it can be run on K1.
Note: The source code can be downloaded from bit-brick’github.
Model Quantization
K1’s NPU does not support direct acceleration of saved h5 models. The model needs to be quantized first and then converted into tflite format. Only then can its NPU acceleration be enabled on K1.
For knowledge about model quantization, refer to:Tensorflow模型量化(Quantization)原理及其实现方法 – 知乎 (zhihu.com)
Model quantization is the process of approximating the continuous floating-point model weights (usually int8) to a finite number of discrete values at a lower loss in inference accuracy. It is the process of using a data type with fewer bits to approximate 32-bit limited-range floating-point data, thereby achieving the goals of reducing model size, reducing model memory consumption, and speeding up model inference.
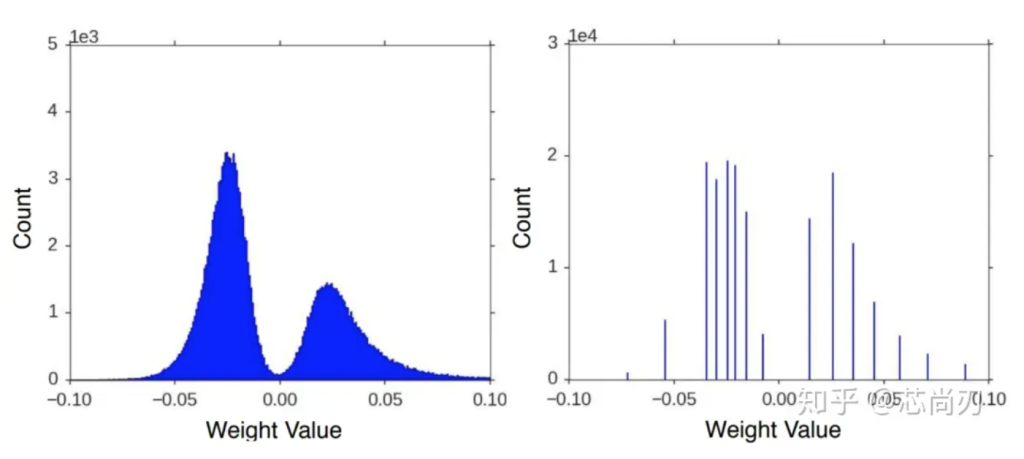
Convert quantized model
There are two ways to convert the model:
For the Tensorflow model, you can use the quantization reference code provided by Google and write it into a Python script for quantization:https://www.tensorflow.org/lite/performance/post_training_quantization
Use the following script to quantize the saved model mnist_model.h5 and convert it into mnist_model_quantized.tflite that can be run on K1.
# convert_to_tflite.py
import tensorflow as tf
import numpy as np
def representative_dataset_gen():
for _ in range(250):
yield [np.random.uniform(0.0, 1.0, size=(1, 28, 28, 1)).astype(np.float32)] #Required input size
def convert_model_to_tflite(model_path, output_tflite_path):
"""
Converts a saved Keras model to TFLite format with post-training quantization.
Args:
model_path (str): Path to the saved Keras model.
output_tflite_path (str): Path where the TFLite model will be saved.
"""
# Load the saved model
model = tf.keras.models.load_model(model_path)
# Convert the model to TFLite format with post-training quantization
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.float32
converter.inference_output_type = tf.float32
converter.representative_dataset = representative_dataset_gen
tflite_model = converter.convert()
# Save the TFLite model
with open(output_tflite_path, 'wb') as f:
f.write(tflite_model)
print(f"Quantized TFLite model saved at {output_tflite_path}")
# Call the function with your paths
convert_model_to_tflite('mnist_model.h5', 'mnist_model_quantized.tflite')2、You can use the eIQ toolkit provided by NXP
Go to the eIQ official website: https://www.nxp.com/design/software/development-software/eiq-ml-development-environment/eiq-toolkit-for-end-to-end-model-development-and-deployment:EIQ-TOOLKIT and download the latest version of the eIQ toolbox.
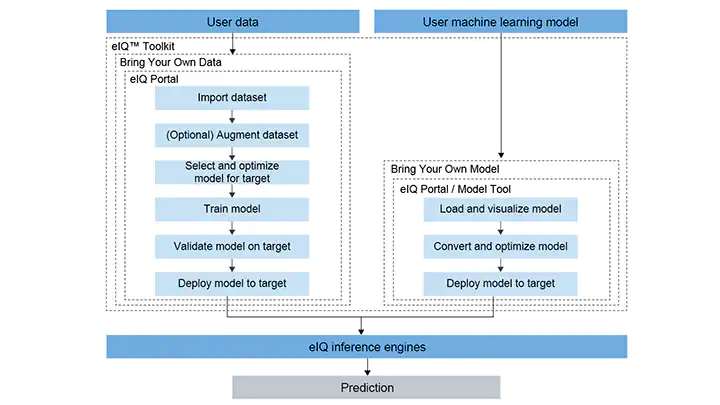
Formats supported by EIQ toolkit for quantification
Tips: EIQ toolkit adds a GUI, which can be used for quantification. In fact, it also calls Google’s TF Lite quantization.
Test model
Put the following script predict_tflite.py in the same folder as mnist_model_quantized.tflite and test_images, and then run predict_tflite.py
import tensorflow as tf
from PIL import Image
import numpy as np
import os
class Predict(object):
def __init__(self):
print("Current working directory:", os.getcwd())
checkpoint_dir = './'
tflite_model_path = os.path.join(checkpoint_dir, 'mnist_model_quantized.tflite') # 使用TFLite模型文件
# Load the TFLite model and enable npu acceleration
self.interpreter = tf.lite.Interpreter(model_path=tflite_model_path,experimental_delegates=[ tflite.load_delegate("/usr/lib/libvx_delegate.so") ])
self.interpreter.allocate_tensors()
# Get the index of input and output tensors
self.input_details = self.interpreter.get_input_details()
self.output_details = self.interpreter.get_output_details()
def predict(self, image_path):
# Read the image in black and white
img = Image.open(image_path).convert('L')
img = np.reshape(img, (28, 28, 1)) / 255.
x = np.array([1 - img], dtype=np.float32) # Make sure the data types match
# Setting the input tensor of the TFLite model
self.interpreter.set_tensor(self.input_details[0]['index'], x)
# Run predictions
self.interpreter.invoke()
# Get the output tensor
output_data = self.interpreter.get_tensor(self.output_details[0]['index'])
# Since only one image is passed into x, just take output_data[0]
# np.argmax()Get the subscript of the maximum value, that is, the number it represents
print(image_path)
print(output_data[0])
print(' -> Predict digit', np.argmax(output_data[0]))
if __name__ == "__main__":
app = Predict()
app.predict('./test_images/0.png')
app.predict('./test_images/1.png')
app.predict('./test_images/4.png')The execution results are as follows
python3 predict_tflite.py
Current working directory: /home/root/ml/mnist
Vx delegate: allowed_cache_mode set to 0.
Vx delegate: device num set to 0.
Vx delegate: allowed_builtin_code set to 0.
Vx delegate: error_during_init set to 0.
Vx delegate: error_during_prepare set to 0.
Vx delegate: error_during_invoke set to 0.
W [HandleLayoutInfer:281]Op 162: default layout inference pass.
./test_images/0.png
[9.99998033e-01 1.54955798e-10 3.32483268e-08 2.28747174e-10
7.21547755e-09 2.97328828e-10 9.07767628e-07 8.88619178e-11
1.11085605e-07 7.94680602e-07]
-> Predict digit 0
./test_images/1.png
[3.2026843e-08 9.9998003e-01 4.3477826e-08 3.4642383e-10 1.4214998e-05
6.9245937e-10 1.2963221e-07 4.5330289e-06 8.9890534e-07 7.5559171e-08]
-> Predict digit 1
./test_images/4.png
[1.4660953e-11 2.9138798e-06 2.1164739e-07 5.3843197e-09 9.9998480e-01
2.7903857e-09 1.0421110e-09 1.6107944e-07 1.0431833e-07 1.1799651e-05]
-> Predict digit 4
It can be seen that the recognition result is accurate.

